
The main problem I have with neural networks for computer vision is that they do not give me understanding. Even the best network, that has a 99.91% accuracy on the MNIST handwritten digits dataset, can not give me any insight. It does not allow me to observe how it actually performs its classification.
I can study the architecture and thoroughly understand all its mechanisms, but the functionality is hidden in the weights of the network. And there might be millions of them.
It may be my training as a physicist, but I like vision systems to be based on a clear theory. I want to be able to understand how it works. A mathematical theory helps me get to the heart of the phenomenon.
For example, take my formula for determining the size of a ball resting on the groundfloor from 1 photo. The formula for the radius 
![A =\frac{p[p+(1-s) - 2\sqrt{p(1-s)}]}{[p-(1-s)]^2 } H](https://s0.wp.com/latex.php?latex=A+%3D%5Cfrac%7Bp%5Bp%2B%281-s%29+-+2%5Csqrt%7Bp%281-s%29%7D%5D%7D%7B%5Bp-%281-s%29%5D%5E2+%7D+H+&bg=ffffff&fg=111111&s=3&c=20201002)
It depends on the height of the camera 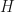


There is not a single parameter in this formula. Perhaps more importantly, it gives extremely accurate experimental results.
Quite a number of assumptions has gone into this formula, but there is no dataset, no training, no adjustments of weights in a network. There is only a clear deterministic mechanism that gives very accurate results in situations in which the assumptions are valid.
I am not against neural networks. They show some amazing capabilities. But I am uncomfortable with them. I prefer understanding.
