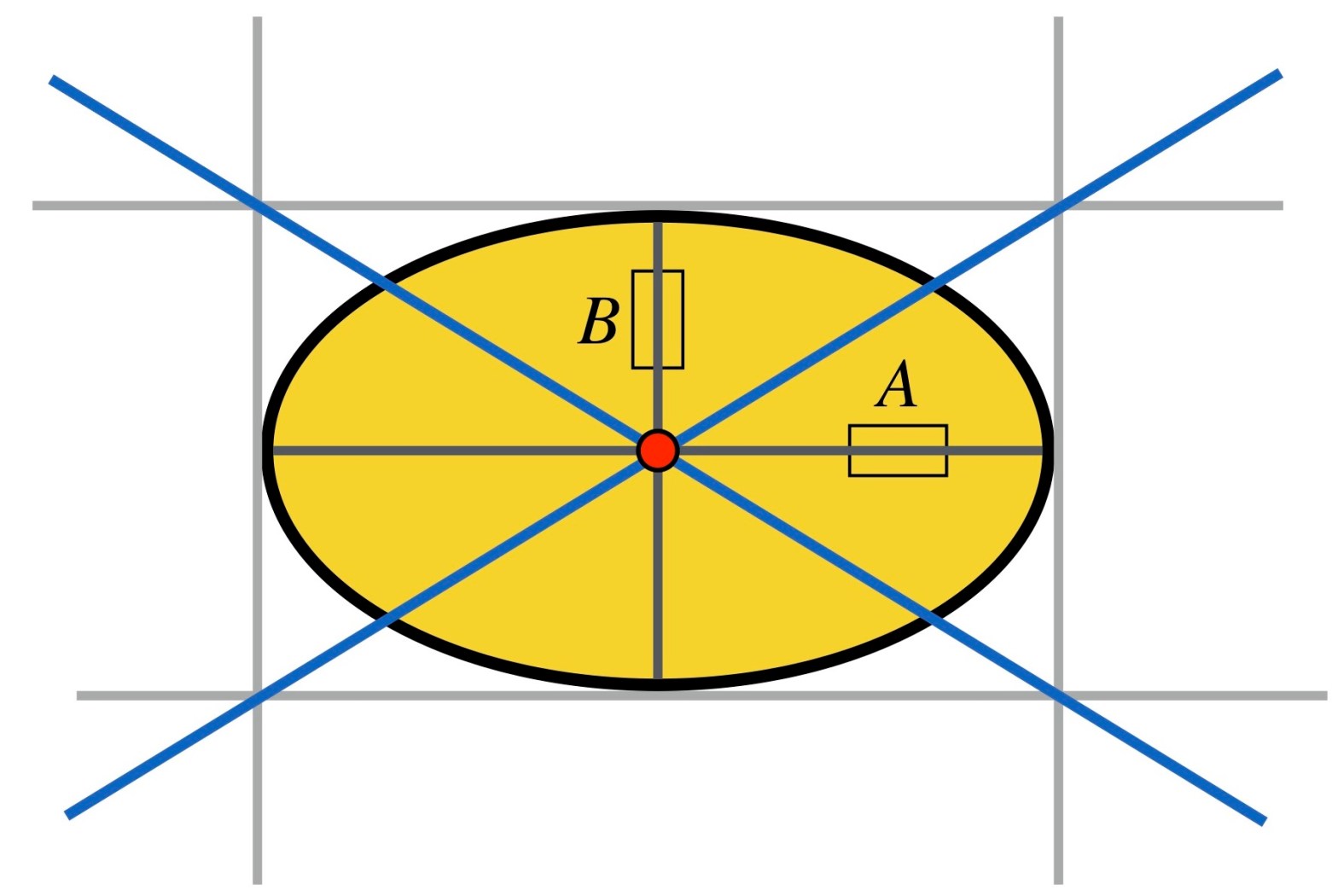
When you look at the photo above, what sizes do you think those 5 spheres have?
If I tell you that the sheet of paper on the right is an A4. And the photo is taken in my office with the camera lying flat on the edge of my desk. Do your estimates change?
Continue reading “Visual geometry of a sphere”